SketchUp Makes Bathrooms Nicer
We’ve gone through our first round of remodel-hell trying to get our master bath in shape. The upstairs master bath had carpet which was basically a deal-breaker for Bety, and coming from our much smaller apartment we didn’t really feel the need to use the full master.
We knew we wanted to tile the bath but also knew that once we tiled we would be locked in to the major layout so any changes to make had to be made in conjunction with laying tile.

Previous Owner
|

Stripped Wallpaper
|
We kicked around a few ideas but the one that stuck was swapping the existing guy’s vanity and the shower. Both were reasonably well “plumbed” for supply, venting, and drainage, and since the “guy sink” was “extra” and obnoxiously large anyway it made a lot of sense to use that area and build out a larger shower in that vanity location.
I got started measuring and modeling the bathroom, as that was something “free” I could do, and it turned out that doing the model was extremely helpful in order to make things “look right” or get a sense of scale. Much easier to demolish a wall in SketchUp than in real life, and a heck of a lot quicker to paint the walls a different color too!
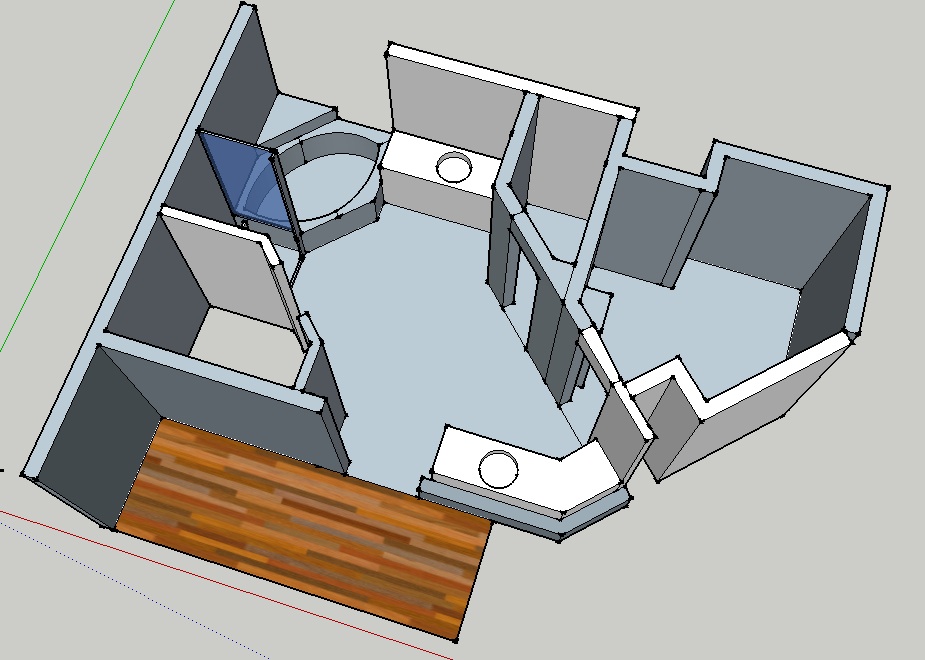
Rough “Pre” Overview
|
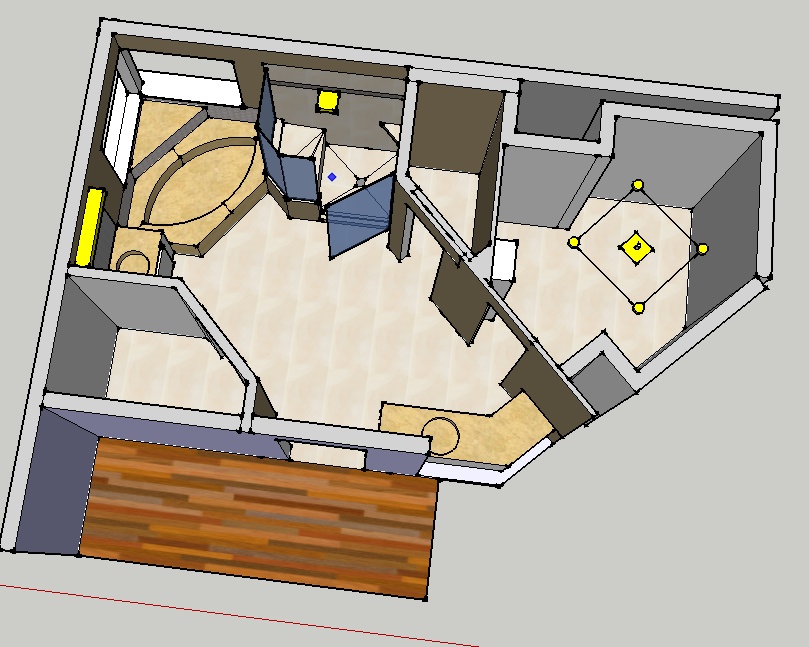
Better “Post” Overview
|
The model on the left is the basic “pre” model and the model on the right is “improved” and slightly more true-to-life. It let us play with heights for the shower wall, get an idea of whether the new vanity location was “big enough”, see where / how the lights might look, how the tile colors and wall colors would interact, etc.
Highly recommended if you have the chops to get a model going in SketchUp again because it makes simulating things so much easier. Other things we considered were enlarging the “throne room”, messing with closet walls, making one of the vanities a “sit-down” style, and it was easy to poke a hole into SketchUp and check sight lines or materials / paint colors to see how it would look.
Using SketchUp also allowed us to realize that we’d need to add / move some electrical around, especially the light-switch which would originally have been near the shower door. Putting in the virtual shower-door forced us to come to terms with the fact that the original switch and switchplate would have been uncomfortably close to the shower opening and that moving it over to gang up with the closet light (and adding an over-shower light) was a good choice.
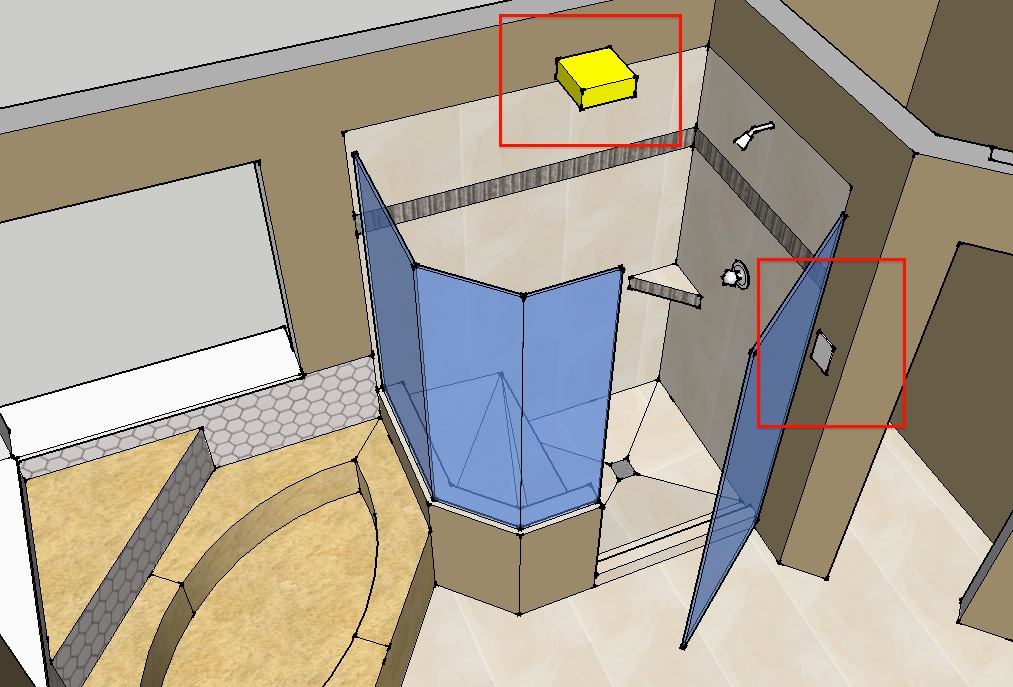
Electrical Annotations
Having the 3D model made it a lot easier to explain things to the contractors that we ended up working with. Which is a whole ‘nother story but one that I might as well tell now.
We’d previously worked with a plumbing company to fix our main sewer line which had a root incursion. We liked the work and attitude of the plumber who was assigned to our job kept a hold of his information for future plumbing needs.
Long story short this plumber was not the right person for our bathroom job. It’d take another wordy document to describe all the mistakes made by the plumber (and delays caused) but the one that stands out is that he originally didn’t think it necessary to affix the shower drain to the subfloor (duh?) and instead left it kindof floating with the pan-liner plastic kindof wadded up in a ball all over the place. This caused me to start looking into plumbing codes (Section 405.4 and 417.5.2 specifically) and tile forums realizing that there wasn’t a single thing right with the way things were going. Ugh.
But I have to look at it as a blessing in disguise because between Larry, Moe, and Curly that were the plumber, “general” contractor, and his assistant we’d picked to do the work, it forced me to really learn how a proper shower is put together, and how improper everything was going compared to how it should have been done.

Had to rip this work out
The contractor came highly recommended as having done work for area restaurants. According to him he had just landed a job doing the wet area for an entire gym being built in Lewisville.
As you might be able to tell, I had a pretty clear idea of what we wanted, the work required and I broke down a punch list of all the major areas and subtasks to make it all happen.
He wrote a quote that was a bit higher than we were expecting but we went back and forth trying to figure out ways to bring down the cost (we’d do paint + trim + demo + garbage disposal saving ~10-20%) and kindof came to an agreement on how to get started. With luck we wanted to be close to finishing from the first weeks of October to just before Thanksgiving when a friend of Bety was coming to visit.
The first warning sign came when he was willing to lay tile directly onto the plywood subfloor. Picking out all the finishings / material was a whole different mess that took a lot of time, and I’d have been damned if he was going to lay this not cheap (but not expensive) tile we’d picked straight onto a plywood subfloor.
The two three lines that immediately came to mind were “That’s now how they do it on TV”, “Show me on the Manufacturers Installation Instructions where it says that you can lay tile directly on plywood”, and “Oops, I guess I didn’t specify that I wanted the work done correctly.”
His response was “If you get tile installation from Home Depot they’d lay it just like this.” Which may or may not have been the case, but I wasn’t in the business of finding out. “It’ll cost more” he said. “That’s fine, just so long as it’s done right” was my reply.
Then we had finally gotten to the point where the plumber had the rough-in inspection passed, the waterproof shower pan liner attached to all flat surfaces, and I had a chance to re-hang the shower wall cement backer board (myself!?!) and had waterproofed it, we called the contractor back.
“Great,” said the contractor. “Let me just poke screw-holes through your waterproof membrane and into this untreated plywood.” Which if you’re not technically inclined is a bit like saying “Let me drive your Ferrari into that brick wall over there.”
Poke holes into my waterproof membrane that I’d spent so much effort with the plumber getting installed right and plumbing passed? No thanks.
At this point the relationship between me and the contractor was in a word “strained” and I needed a third party expert to give me a somewhat neutral, fact-based opinion.

New Contractor - Redoing Work
My stroke of genius was to call the shower-glass company and ask them if they had any contractors they recommended. There may be 1000+ contractors in Dallas, but proportionally much fewer companies that install the end-product shower glass enclosures. I wanted a connection with somebody the glass company saw a lot of, not with HandyMan2.0 who may or may not know anything about bathroom remodels.
Chris from Pineapple Home Creations was able to swing by and confirm my suspicions and more. That the work done up to that point was likely not going to last more than a year or two without significant problems. “Great… give me a quote.”
The most frustrating thing about this whole experience was that the quote and labor charged by Chris was pretty much exactly the same as the price charged by the original contractor, except where things cost more in order to do it the right way. ie: the flooring installation cost an extra $500 in order to install our tiles over a better (ditra-mat decoupling membrane) subfloor. All labor rates were the same except where he could point to something and say: “That… that costs you more but it’s done right and will last.”
So it was an expensive lesson to have started with a crappy plumber and somewhat crappy contractor, but “worth it” to be able to sleep well at night and not have that fear of liability where you’re worried that your shower might leak, or mold might be growing and rotting your wood. It’s scary to have work done on your place and comforting to have confidence in the work that’s been done.

Surface Prep

Majority Tile Work

Painted And Grouted
The work progressed pretty quickly after the initial false start and we are now just waiting on final glass installation and for me to do miscellaneous trim work (baseboards, towel-holders, etc).
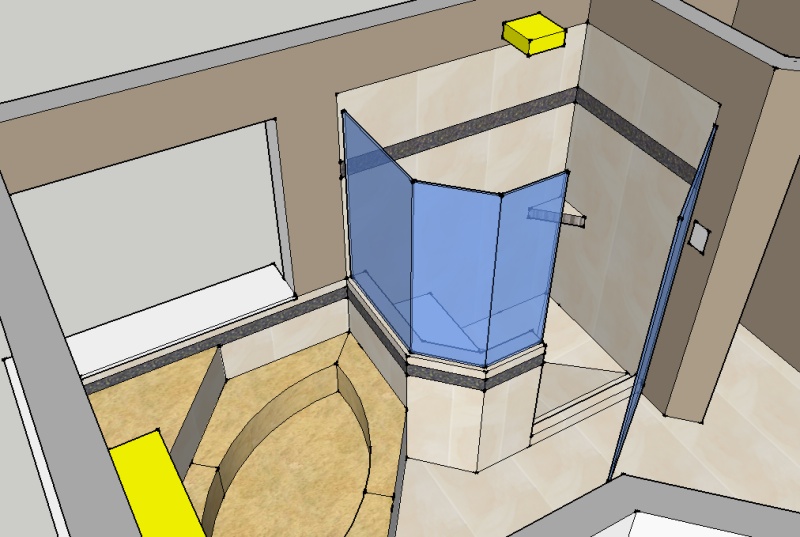
Shower Model
|

Shower Actual
|
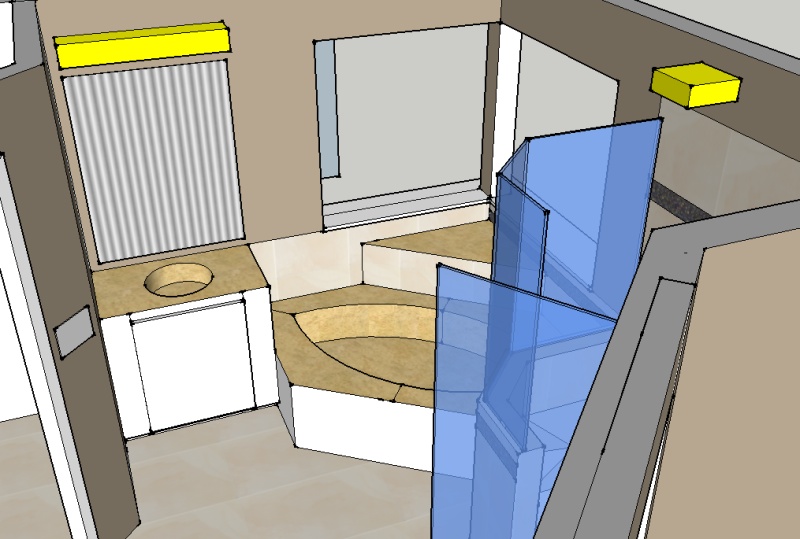
Vanity Model
|

Vanity Actual
|
In some ways it’s pretty amazing to see the model compared to actual results. The pictures aren’t the greatest, as you can see there is still work to be done (mirrors, trim, cleanup). With luck I’ll be able to update this info to show the true final product and see how it compares.
11:46 CST | category / entries
permanent link | comments?
Git in Two Ten(?) Minutes.
I’ve only got two ten(?) minutes so I’ll make this quick.
Git identifies everything uniquely by “SHA1’s” based on the contents. We will use the following SHA1’s as examples representing “commits” in a simplified git repository.
echo git1 | sha1sum = 4975febf96488bd932313aa2846ab0c89860cdb8
echo git2 | sha1sum = 70d5b110333a87a17dc2eb4f42506ae3f57c5b13
echo git3 | sha1sum = bf18d75b5761252f9c70a3f300cb03a2497b1d6e
echo git4 | sha1sum = ab3ac50a9c033bb43687e27f066463db1497b714
echo git5 | sha1sum = 1a7bf3c387128af2faef58834d7bbdacd16e477b
Git basically operates as a linked list, one of the most fundamental structures in programming. Think of the SHA1’s as pointers. Each “commit” is uniquely identified, and has a reference to the commit that came before it (its “parent”).
[
{
'parent': null
'sha1': '4975febf96488bd932313aa2846ab0c89860cdb8',
},
{
'parent': '4975febf96488bd932313aa2846ab0c89860cdb8'
'sha1': '70d5b110333a87a17dc2eb4f42506ae3f57c5b13',
},
{
'parent': '70d5b110333a87a17dc2eb4f42506ae3f57c5b13'
'sha1': 'bf18d75b5761252f9c70a3f300cb03a2497b1d6e',
},
{
'parent': 'bf18d75b5761252f9c70a3f300cb03a2497b1d6e'
'sha1': 'ab3ac50a9c033bb43687e27f066463db1497b714',
},
{
'parent': 'ab3ac50a9c033bb43687e27f066463db1497b714'
'sha1': '1a7bf3c387128af2faef58834d7bbdacd16e477b',
}
]
I’m actually going to re-write this with a slightly different data structure (a hash, keyed by the unique identifier and its parent):
{
// SHA1 // PARENT SHA1 // "name"
////////////////////////////////
'497...': null, // (git1)
'70d...': '497...', // (git2)
'bf1...': '70d...', // (git3)
'ab3...': 'bf1...', // (git4)
'1a7...': 'ab3...' // (git5)
}
If I say “Tell me the history of 1a7bf3c387128af2faef58834d7bbdacd16e477b”, you put your finger on 1a7..., see that its parent is ab3... and can trace the history back until the very beginning 497....
We have two concepts. A unique identifier (SHA1) and the fact that each SHA1 knows its parent (the “linked list”).
If I ask you to point to bf1... we can walk backwards to 70d... using the “parent” reference, but not “forwards” to ab3... unless you scan all the SHA1’s looking for things that refer to bf1... (which is a slow operation).
The reasoning behind this is because when you’ve commited bf1... to git, it’s impossible to know what your next commit will be. Will it be to [fix bug 123]? Or will you [fix bug 456]? Or will you [add feature FOO]? What if you did all three simultaneously?
Now to introduce two new SHA1’s.
echo git4b | sha1sum = 37bc26b0971807ff72bf1a2ac1e2e2d2bca7d53e
echo git5b | sha1sum = 7f4aab0b9f240fe0293fe2df10225a2ef4a468c7
These represent an alternate future where instead of committing git4, git5 on top of git3 we commited instead git 4b, git5b. Now we have an ASCII picture:
497...(git1)
^
|
70d...(git2)
^
|
___bf1...(git3)
/ \
ab3...(git4) 37b...(git4b)
^ ^
| |
1a7...(git5) 7f4...(git5b)
And that’s git. Git doesn’t care what those numbers mean, it just lets you track them “easily”. Updating our example hashmap from above.
{
// SHA1 // PARENT SHA1 // "name"
////////////////////////////////
'497...': null, // (git1)
'70d...': '497...', // (git2)
'bf1...': '70d...', // (git3)
'ab3...': 'bf1...', // (git4)
'1a7...': 'ab3...' // (git5)
'37b...': 'bf1...', // (git4b)
'7f4...': '37b...' // (git5b)
}
You can point to 1a7... and walk all the way back to 497... or put your finger on 7f4... and get back to 497... because it is basically a linked list.
Using this simple data structure, you have just implemented local branching. You can switch back and forth between 1a7... and 7f4... very easily. The history is different between the two “branches” but everything from bf1... and above is “shared history” between the two “branches”. These separate branches exist simultaneously and are fundamentally impossible to conflict because each has a complete history all the way back to the first commit: 497....
The final concept to introduce is “synonyms” or “branches”. Since it’s impossible for humans to deal only with 1a7... or 7f4... git will let you “name” branches. You can call 1a7... “trunk” or “master”. You can call 7f4... “beta”. The names are important to the humans using the system, but not to git.
Remember when we weren’t sure if the next step after bf1... was going to be to fix bug 123, 456, or implement feature “foo”? If you have three developers on three different computers, they can each be working on those three different tasks. As a matter of fact, the goal of every modern version control system is to have different developers at different computers working on different tasks simultaneously.
Fundamentally, if everybody “knows” that the most recent version is bf1... there are an infinite number of things that could happen after bf1.... The development process when using git is for individual developers to create these new possible histories locally on their computer, somehow decide that one of those histories is “the new most recent version”, and convince the world that new changes should be based on that new “most recent version”, or at least take that new version into consideration.
There are no “practical” git commands in this description of git and here ends our two ten minutes. But given the above mental model I can assure you you’ll understand the following (assuming you’ve already got a copy of a git repository on your machine via git clone ... or similar):
$ git checkout 1a7
...makes the files in your working directory match the full
history of 1a7bf3c387128af2faef58834d7bbdacd16e477b above
$ git checkout 7f4
...makes the files in your working directory match the full
history of 7f4aab0b9f240fe0293fe2df10225a2ef4a468c7 above
(this is "switching branches")
$ git checkout -b bug-1234-fixing-some-thing 7f4
...this makes "bug-1234-fixing-some-thing" be a synonym for
the full history 7f4aab0b9f240fe0293fe2df10225a2ef4a468c7
$ git checkout -b trunk 1a7
...this makes "trunk" be a synonym for the full history
of 1a7bf3c387128af2faef58834d7bbdacd16e477b
$ git checkout bug-1234-fixing-some-thing
...this "switches branches" again back to
7f4aab0b9f240fe0293fe2df10225a2ef4a468c7 because 'bug-1234-fixing-some-thing'
is literally just a synonym for 7f4aab0b9f240fe0293fe2df10225a2ef4a468c7
...notice the lack of "-b" since the branch / synonym / name already exists
$ git checkout trunk
...this "switches branches" again back to
1a7bf3c387128af2faef58834d7bbdacd16e477b because again, trunk is literally
a synonym for 1a7bf3c387128af2faef58834d7bbdacd16e477b
...again notice the lack of "-b" since the branch already exists
If you understand that a branch / branch name is just a synonym for these unique SHA1 identifiers (and by implication this includes their full and complete history) you are doing great!
So back to our scenario from above what we’ve done is put labels on the two different histories. Let’s put one more label on things now:
$ git checkout -b v1.2.3 bf1
...this makes "v1.2.3" be a synonym for the history from bf1...
back to the first commit (497...)
497...(git1)
^
|
70d...(git2)
^
|
__bf1...(git3)
/ v1.2.3 \
/ \
ab3...(git4) 37b...(git4b)
^ ^
| |
1a7...(git5) 7f4...(git5b)
trunk bug-1234-fix-some-thing
So now we can reason a little bit better about everything. bf1... was released to production as “version 1.2.3” and then there was some development done on trunk, but there was also a bugfix done to fix bug 1234. Let’s say that the bugfix for bug 1234 hasn’t been shared with anybody yet (it’s still on the local developer’s computer, or hasn’t been pushed to production or integrated into “trunk”).
Git gives us two very compelling options:
In scenario #1, how do we do it? Well we want 7f4... to go out to production so we add a label to it:
$ git checkout -b v1.2.4 7f4
...this makes "v1.2.4" be a synonym for the history from 7f4...
back to the first commit (497...)
Showing the changes on the tree:
497...(git1)
^
|
70d...(git2)
^
|
__bf1...(git3)
/ v1.2.3 \
/ \
ab3...(git4) 37b...(git4b)
^ ^
| |
1a7...(git5) 7f4...(git5b)
trunk bug-1234-fix-some-thing
v1.2.4
Then run your normal release process to push out 7f4... to production (copy files, build packages, whatever).
You’ll notice that now 7f4... now has two “synonyms”. That’s easy enough to fix…
$ git branch -d bug-1234-fix-some-thing
remove the now redundant label that points to 7f4
Excellent! We’ve now fixed and released a critical bug in production without disturbing the normal development process.
But what if the bug wasn’t super-critical and should just be batched up with all the other fixes?
This is where there is some disagreement in the git community around “linear” history, “rebasing” and “merging”. Just hold your breath and remember that git is a linked list. And now to fully disclose, I lied a little bit about git being exactly a linked list. Git commits can actually have one or more than one “parent”.
Let’s look at a “merge” commit, but I need to introduce a new SHA1:
echo 1a7,7f4 | sha1sum = c2804854f39203f53a4cbf1fd4e17dfef218fd17
This is trying to represent a new commit which has two parent references in order to let you traverse both the 1a7... and 7f4... histories.
497...(git1)
^
|
70d...(git2)
^
|
__bf1...(git3)
/ v1.2.3 \
/ \
ab3...(git4) 37b...(git4b)
^ ^
| |
1a7...(git5) 7f4...(git5b)
trunk bug-1234-fix-some-thing
\ /
\__ ______/
^
|
c28...(git6) - has pointers to both 1a7 and 7f4
So, now we have a new SHA1 c28... that points two both 1a7... and 7f4... as parents. We still don’t know what the future holds, but we know for sure how we got here. And we haven’t given c28... a name yet. Howabout “trunk”?
497...(git1)
^
|
70d...(git2)
^
|
__bf1...(git3)
/ v1.2.3 \
/ \
ab3...(git4) 37b...(git4b)
^ ^
| |
1a7...(git5) 7f4...(git5b)
trunk bug-1234-fix-some-thing
\ /
\__ ______/
^
|
c28...(git6) - has pointers to both 1a7 and 7f4
trunk
In git this is called a “merge commit” because it has two parents. Some people like it because it clearly segregates the fact that the development for 7f4... happened separately, it was based off of bf1..., there’s a very rich history and metadata about how the change occurred. although in a repository with many merge commits the little “merge bubbles” that appear in the history can sometimes be hard to understand.
The other option is called “rebasing”. It’s when you take the history or changes from one branch and pretend it happened on a different branch or in a different way. Going back to the original situation:
497...(git1)
^
|
70d...(git2)
^
|
__bf1...(git3)
/ v1.2.3 \
/ \
ab3...(git4) 37b...(git4b)
^ ^
| |
1a7...(git5) 7f4...(git5b)
trunk bug-1234-fix-some-thing
What if we want to just move our bug-1234 changes over to trunk and pretend that we made them there in the first place?
$ git rebase 1a7 7f4
...replay the changes from `7f4...` onto `1a7...`
Or using synonyms (aka: “branches”):
$ git rebase trunk bug-1234-fix-some-things
Now, remembering that git has SHA1’s and “parent” references, we can’t actually put 7f4... and 37b... after 1a7.... This is another little detail about the git format. Each SHA1 actually cryptographically “signs” or includes the parental history reference. The parent of 7f4... will always be 37b... and is impossible to change. So we can’t actually move 7f4... on to 1a7... as is. BUT what we can do is replay the change history from 7f4... “on top of” 1a7.... It’s a subtle but important distinction. You’re making the same changes but with different parent references. In order to show how this works I’ll need to introduce some new SHA1’s.
echo git6 | sha1sum = 27ce3159f636bbc1645237bd51ae852391ec7596
echo git7 | sha1sum = 07282395ce8f4b29df2811c1ce74c06f9ca13898
These two SHA1’s can be assumed to be exactly the same changes described by 37b... and 7f4... respectively, but just with their parent references adjusted to be “played back on top of” 1a7..., giving us the following picture.
497...(git1)
^
|
70d...(git2)
^
|
__bf1...(git3)
/ v1.2.3 \
/ \
ab3...(git4) 37b...(git4b)
^ ^
| |
1a7...(git5) 7f4...(git5b)
trunk bug-1234-fix-some-thing
^
|
27c...(git6) - used to be git4b
^
|
072...(git7) - used to be git5b
Git at this point has been convinced that the 37b... and 7f4... changes actually were “based on” 1a7... when they were originally based on bf1.... And this is why the community is split on the “validity” or “correctness” of rebasing vs. merging.
In the merge scenario, you can see exactly the actual development history of how the two branches started from a common ancestor and eventually came back together. With rebasing, you “lose” the fact that the changes actually happened in a different order or in a different place but in many cases that ordering or common ancestor information is not actually relevant.
It is important to note that, unless you explicitly tell people about the 7f4... reference, that history and data is not shared or available to anyone else and would eventually be lost.
The way git works, no data is actually ever “lost” locally even after rebasing because git still keeps around the information (at least locally) about the 7f4... history. The local copy just now has two new additions to the tree… 27c... and 072.... And we need to fixup the references.
497...(git1)
^
|
70d...(git2)
^
|
__bf1...(git3)
/ v1.2.3 \
/ \
ab3...(git4) 37b...(git4b)
^ ^
| |
1a7...(git5) 7f4...(git5b)
trunk bug-1234-fix-some-thing
^
|
27c...(git6)
^
|
072...(git7)
bug-1234-fix-some-thing
Actually git will normally upate the synonyms / branch references for us automatically, doing “the right thing” without any issues. But since you’re now an expert on how git works, you know that you could put these “branches” / “labels” / “synonyms” anywhere you’d like.
If you’d like to convince the world that 072... is now the latest and greatest, well… just call it “trunk” now.
497...(git1)
^
|
70d...(git2)
^
|
__bf1...(git3)
/ v1.2.3 \
/ \
ab3...(git4) 37b...(git4b)
^ ^
| |
1a7...(git5) 7f4...(git5b)
^
|
27c...(git6)
^
|
072...(git7)
bug-1234-fix-some-thing
trunk
…and you should notice pretty quickly that the “bug-1234-fix-some-thing” synonym is now redundant and the synonym could be deleted. You should also notice that 7f4... can’t be reached by any of the “named branches”. Eventually git will expire these orphan commits and garbage-collect them but they still exist at least on your local hard drive. If you want them to be available to other people you have to publish them, name them, and make them available, but since the important information has been transmitted over to the “trunk” branch, it’s often not very useful to share that information.
The biggest point to realize is that if you’ve made a commit and gotten a SHA1 from git, it’s almost impossible to “lose” data with git. Because the base git data structure is so “simple”, any SHA1 will give you an exact reference from tip to tail of the exact, cryptographically secure state of every bit of data along that chain.
So when people tell you that “git lost my data” the most likely scenario is that git may have “lost” or overwritten uncommitted data in their working directory. Until you get used to the malleability of git’s history tree you might be “scared” of committing work that isn’t ready, but in actuality, committing is the safest thing you can do in git. If you commit something in git, you can always get back to it, bit-for-bit, and you can always “undo” it because you can always just restore things to the way the parent was.
The most dangerous time in any version control system is when you have changes that aren’t committed and triply so in git because that is the only time you have a non-zero chance of really losing your data. Most of the time git will avoid losing or overwriting local data but as far as I can remember off the top of my head, only git clean ... can be manipulated to delete files that aren’t checked into git, and git reset ... can be run in a way that overwrites your local uncommitted changes with an old state of the repository. In both of those cases the “only” work that is at risk is work that has not been committed, so if you have any doubt whatsoever, it is better to err on the side of adding a local commit or make a backup of any files or changes that you’re not sure about.
I think I’ve gone over my ten minutes now, but I hope that this conceptual overview is helpful to reason about git. My goal has been to take out some of the “mystery” of git but leave the “magic”. Once you understand that git is very easy, almost “simple” to understand and reason about, the mystery goes away and you are left with the ability to do magic.
10:56 CST | category / entries
permanent link | comments?
Google App-Engine “Doesn’t” Scale
I agree for the most part with your final conclusion: “no system that is
likely to become productionized at scale should be written on App Engine.”
This is a sad conclusion to arrive at after all these years, especially when
the original promise of App Engine was (essentially) “write your applications
against our strange, quirky API, and they’ll scale far more cheaply and
reliably than they could otherwise.”
[source…]
I’m going to have to add fuel to the fire here, 100% agreement.
GAE is “irreplaceable” in the sense that while the API has been mostly duplicated, the ability to scale that API to arbitrarily large workloads has not.
There was a blog article a long time ago that talked about designing a future language and came to the conclusion that perhaps even performance characteristics should be specified. For example, a language where sort might have n^2 vs. n log n performance characteristics will work fine for basic workloads but will wreak havoc when used at higher capacities. Specifically, after a certain point, performance expectations become part of the implementaiton.
So you have GAE, which has incredible “Superman” powers, faster than a speeding bullet, more powerful than a locomotive, etc. and irreplaceable for automatically scaling to arbitrarily large workloads. And therein lies the rub, as described in the linked article.
The one feature that GAE gives you, the reason you’re sacrificing everything to work in GAE’s world is the one feature you can’t count on. You can’t count on it due ENTIRELY to the mismanagement by Google of their GAE developer community. E-N-T-I-R-E-L-Y. It is a good thing Netflix made their pricing and customer-rlation screwups after Google did otherwise I would say they had “Netflix-level” poor planning and communication.
Actually there are two reasons. One is that GAE cannot be replaced (there is no alternate GAE provider that can scale to some arbitrary 1TB workload) and two is that GAE so poorly mismanaged the “transition to non-beta” product for GAE.
A few years ago I sung the praises of Google’s strategy with GAE and Adwords. I would tell people: “Where is autos.google.com?” And autos.google.com is actually google.com/search?q=autos because every auto forum is running Adwords against their content. And then they launched GAE and my expectation was that a lot of the autos websites (mysweetcorvette.com) would transition to using a GAE-based forum and google would make yet-even-more-money hand over fist.
They give you the tools to get started capturing users and generating content, the tools to monitize it, and the more users / monetizing you get you bump from the GAE free tier to the GAE pay tier. Of the $100/mo you get from Google Adwords, you start paying $1/mo to Google and earning $102 from Adwords. Then $10/mo to Google and earning $120 from Adwords as your userbase continues to grow.
But alas, this wasn’t meant to be. Google has a unique, challenging, irreplaceable developer product to use and the one thing it excels at (scaling) is the one thing that is impossible to trust.
At this point, I imagine that Amazon’s EC2 + “Individual Dumb Services” is far better compared to Google’s style (which doesn’t bode well for future Google acquisitions……). S3 is too expensive? Move to a different “I serve files from big hard-drives” provider. SimpleEmail not doing it for you? Get on board with a different “pay-to-spam” provider. EC2 doesn’t match your needs? Find a different cloud provider and have a minimal implementation up and running on them.
Amazon, by designing their services around commodity components that encourage competition and API duplication has paradoxically made their service more architecturally robust (in the sense that a customer has tons of options for migration, price, and performance competition). Downtime(s) notwithstanding, it looks like the original blog author has hit the nail on the head.
EC2-style implementations require a bit more work up front but leave you in a more price-competitive situation if your product takes off and gets a lot of traffic. And your product won’t. 99.9% of the time you’re gonna be fine with a single box or a 4-box setup (2 frontend, 2 database). And if you do reach the giddy heights of needing GAE’s scalabilty, you have to begin each SEC filing with: “Assuming Google doesn’t raise prices for app-engine by ∞% like they did last year …”
Enjoy the Ferrari, Google and I guess everybody else will stick with their daily drivers.
11:57 CST | category / entries
permanent link | comments?